

Introduced by Google in 2017, Transformer models have been a revolutionary concept in machine learning. Offering a paradigm shift in sequence transduction, this novel neural network architecture has significantly enhanced the efficiency and accuracy of various AI applications, enabling breakthroughs in tasks such as natural language processing, speech recognition, and real-time analytics.
Among the many real-world applications of Transformer models, few places see more value from the concept than edge computing tasks. However, supporting Transformer models while balancing the demands of the edge requires powerful and efficient processing capabilities — and that’s where the Arm Ethos-U85 truly shines.
A Deeper Look at Transformer Networks
Transformer networks are designed for handling sequential data tasks like natural language processing and machine translation.
Unlike traditional models such as recurrent neural networks (RNNs) and convolutional neural networks (CNNs), which rely on sequential processing or convolution operations, Transformer networks utilize a unique self-attention mechanism. This mechanism simultaneously evaluates the relationships between all elements in a sequence and allows the model to weigh the significance of different elements relative to each other. This capability enables the capture of long-range dependencies without regard to their position in the sequence, enabling a greater understanding of context and semantics in tasks like language translation and speech recognition.
Transformer networks enable a greater contextual understanding for applications like information extraction. (Source: NVIDIA).
The architecture of Transformer networks also consists of an encoder-decoder structure. The encoder processes the input sequence to generate a series of internal representations, which the decoder then uses to produce the output sequence.
The encoder and decoder consist of multiple identical layers, each containing two main components: multi-head self-attention and feed-forward neural networks. Multi-head self-attention enables the model to focus on different parts of the sequence simultaneously, enhancing its ability to capture various aspects of the data. This mechanism projects queries, keys, and values into multiple subspaces and applies attention in parallel, thus improving both accuracy and efficiency.
Additionally, Transformer networks incorporate positional encodings to address the lack of inherent sequential processing. These encodings inject information about the position of tokens in the sequence using sine and cosine functions, helping the model distinguish the order of tokens.
Benefits of Transformer Networks for Edge AI
Thanks to their unique architecture, Transformer networks offer a number of key benefits to edge AI computing applications. These include
- Parallelization: Unlike RNNs that process sequences sequentially, Transformers can process entire sequences simultaneously. This parallelization accelerates training and inference times, enabling high efficiency for real-time applications, even on devices powered by small batteries.
- Scalability and Performance: The architecture of Transformer networks can be scaled to fit various computational capacities, making them ideal for a range of Edge AI devices, from low-power sensors to more capable edge servers.
- Performance: Transformer networks provide superior performance through their self-attention mechanism, more effectively capturing long-range dependencies and delivering a more accurate and nuanced understanding of input data.
Deploying Transformer Networks on Embedded Edge Devices
Advancing the capability of Embedded Edge Devices to the point where Transformer networks can be deployed on them will require even higher levels of performance optimizations.
Meanwhile, driving performance higher will make it even more important to increase innovation on the power efficiency side to maintain the overall system balance.
Alif is partnering with Arm to leverage their upcoming Ethos-U85 NPU which, among other upgrades, will be capable of handling an extended set of operators, as well as performing hardware chaining of the operators to minimize data movement overhead. Paired with the available bandwidth in the Ensemble family’s architecture between the NPU and the memory hosting the model being executed, significant performance gains will be achieved for AI/ML workloads.
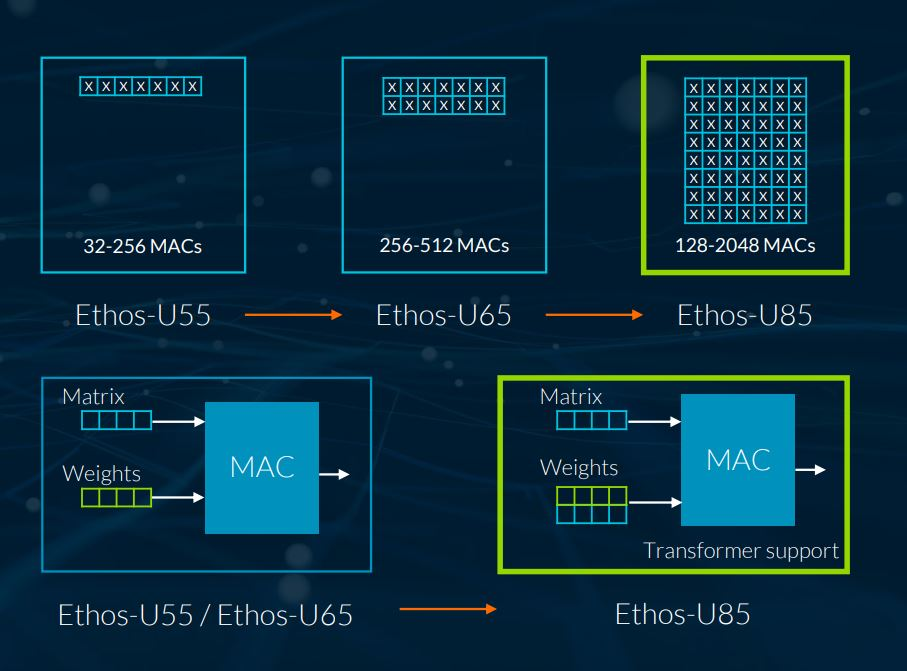
The Ethos-U85 builds off the U55 and U65. (Source: Arm)
Alif Semiconductor’s Future with Ethos
At Alif, we believe that the future of AI lies in bringing powerful, efficient computing to the edge. By being one of the first partners to license Ethos-U85 technology from Arm, we’re leading the charge and providing our customers with a way to realize the benefits of Transformer models in edge applications. Stay tuned for Ethos-U85-based releases in the future.