

When AI and machine learning (ML) first began to be taken seriously in embedded applications at the edge, OEMs tried to run inferencing operations on the same microcontroller with the same CPU that they used for classic control functions. The embedded world soon discovered that this wasn’t ideal: a CPU has the wrong kind of compute architecture for neural networking operations.
What’s needed is a neural processing unit (NPU). This explains the popularity today of MCUs such as the Ensemble family, which combine a CPU for embedded control with an NPU for AI/ML functions, all in a single chip.
So does that mean that an MCU for AI/ML applications just needs a tick in a single check-box: if it’s got a built-in NPU, it’s good for AI?
No – and that’s because the way that the NPU is implemented in the MCU has a massive impact on the inferencing performance factors that designers care about: speed and power consumption.
Alif has been developing edge MCUs with AI capability for as long as edge AI has been a thing. Here are the three big lessons that we’ve learned about how to integrate an NPU into an MCU.
Fast, low-power ML inferencing depends on memory type and topology
A reason to implement ML at the edge, rather than in the cloud, is latency: the user experience normally requires the impression of an instant response.
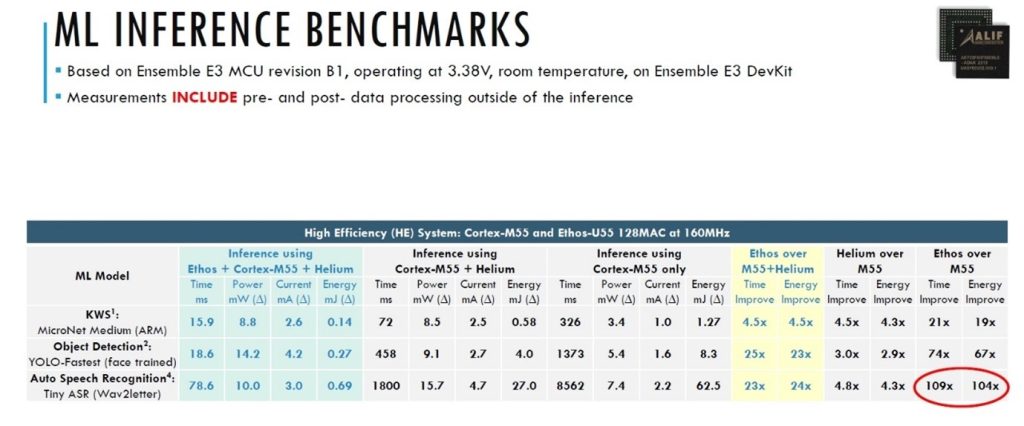
Table showing the difference in AI/ML performance between a CPU and an NPU
This performance comparison table shows how much faster and more efficiently common AI functions run on an Arm® Ethos™ NPU than on an Arm Cortex®-M55 CPU.
What it doesn’t show is how important an optimized memory system is to this high NPU performance.
The diagram below shows the Ensemble products’ memory system. In the top half, very fast Tightly Coupled Memory (TCM) is connected to both the CPU and NPU cores. For fast (low latency) inferences, these TCM SRAM memories must be sufficiently large to hold the ML model’s tensor arena.
The lower half of the diagram shows other memories distributed about the system, and connected by a common high-speed bus. A large bulk SRAM is required to hold sensor data, such as the input from a camera and microphones, and a large non-volatile memory contains the ML model itself plus application code.
When large on-chip memories are distributed this way to minimize competing bus traffic, then concurrent memory transactions flourish, bottlenecks are cleared, memory access times are minimized, and power consumption is compatible with the use of a small battery.
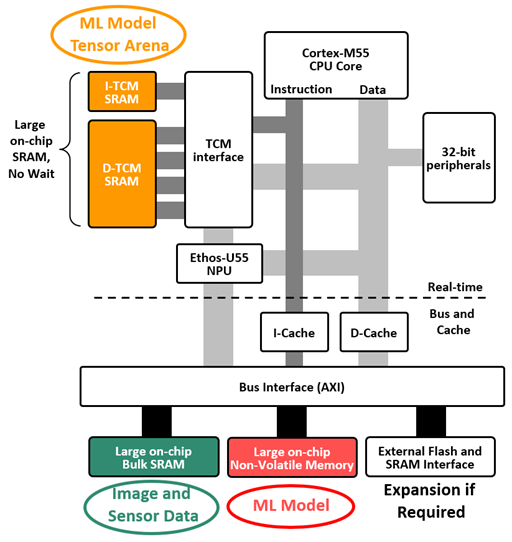
The Ensemble MCUs’ internal memory topology
Battery life matters. A lot.
Smart glasses, fitness rings, and hearing enhancers are examples of AI-enabled wearable devices for which market demand is expected to grow dramatically. All need to be powered by a small battery.
Alif has adopted several techniques for stretching battery life. Two examples are:
- Partitioning the system so that a low-power portion of the chip can be always-on. This always-on segment offers robust compute capability, enabling it to selectively wake a much higher performance portion of the chip to execute heavy workloads then return to sleep
- The power management system dynamically powers on only portions of the chip that are needed and shuts them off when not.
A real-world example of how this dual power topology works is a smart occupancy camera: it continuously scans a room at a low frame rate using a low-power, always-on block to classify a valid event (such as a human falling to the floor). On detecting such an event, it wakes a high-performance/higher-power block to identify a person or persons, check for blocked exits, dial for help, and so on.
In this case the camera can be intelligently vigilant, produce fewer false positives, and extend battery life. The same always-on topology can be applied to the classification of sounds, voices, words, OCR text, vibrations, and sensor data in many varied applications.
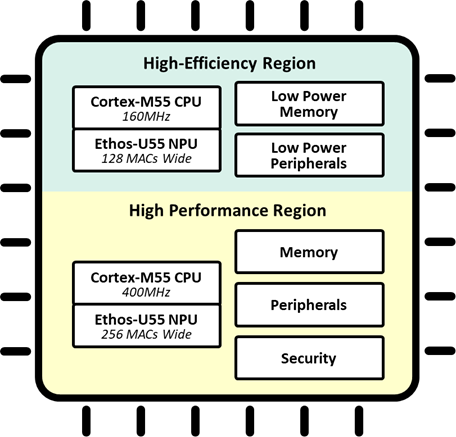
The Ensemble E3 MCU features separate High-Efficiency and High-Performance blocks
Make the NPU easy for developers to work with
AI/ML is a new endeavor for many design engineers, featuring new concepts and new development methods. But at least the development environment can be kept familiar.
The MCU world has standardized on the Arm Cortex-M architecture for embedded control, and now Arm’s Ethos NPUs are joining that robust support ecosystem and enjoying all its familiar benefits. But in the field of embedded NPU engines, a wide choice of other products is available from IP vendors, and some well-known MCU manufacturers are creating their own proprietary NPU IP.
All these other choices, however, take the NPU outside the Arm ecosystem in which embedded control functions are developed. This makes the Ethos NPU a better choice for many users, since it allows AI functions to be developed in the same familiar MCU environment as used for control functions.
In an Ensemble MCU, the Ethos NPU essentially functions as a smart peripheral of a Cortex-M55 CPU to which it is closely tied, sharing TCM resources which are marshalled by the Cortex core. This means that the developer does not need to worry about hardware resource allocation. The Arm compiler simply portions out the ML workload appropriately to the NPU and CPU without requiring specific allocation instructions from the developer.
Get started with the Ensemble MCUs with built-in NPU
We’ve explained here why the Ensemble MCUs’ architecture is ideally suited to AI/ML applications at the embedded edge.
Now it’s easy to get started with the Ensemble family by using the Ensemble AppKit. The kit includes the Ensemble E7 fusion processor, a camera, microphones, a motion sensor, and a color display – and it is available to order today.

Alif Ensemble Application Kit, AK-E7-AIML